
Ragify AI
Upload PDFs and get intelligent, accurate answers powered by advanced Al. No more manual searching through pages of documents.
Timeline
Work in progress
Role
Backend
Team
Solo
Status
In DevelopmentTechnology Stack
Overview
Ragify
Ragify is a Retrieval-Augmented Generation (RAG) system designed to deliver accurate, context-aware AI responses by grounding large language model (LLM) outputs in user-provided documents.
🧠 How It Works
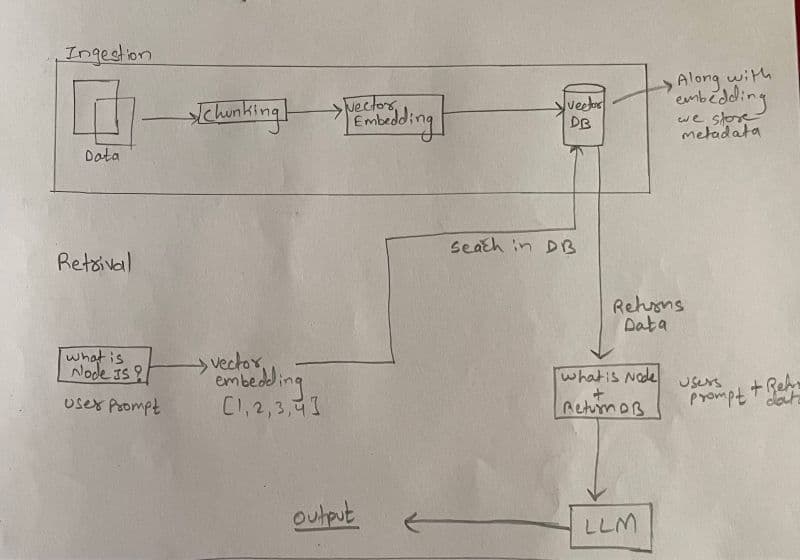
📥 Indexing Phase
- The user uploads a PDF document.
- The content is parsed and split into meaningful chunks.
- Each chunk is converted into vector embeddings.
- These embeddings are stored in a vector database for efficient semantic search.
🔎 Retrieval Phase
- A user query is converted into a vector embedding.
- The embedding is searched against the vector database.
- The database returns the most semantically relevant chunks.
- The retrieved context, along with the user query, is passed to the LLM.
- The LLM generates a grounded, accurate response using the retrieved context.
🎯 Why Ragify?
By injecting document-specific context at query time, Ragify:
- Reduces LLM hallucinations
- Improves factual accuracy
- Grounds responses in user-provided data
- Enables reliable question-answering over custom documents
⚙️ Scalability & System Design
At scale, a synchronous indexing pipeline would become a bottleneck. For example, if hundreds of users upload PDFs simultaneously, the system could overwhelm compute resources and fail during the indexing phase.
To address this, i have implemented an asynchronous, distributed queue-based architecture:
- PDF processing and indexing jobs are pushed to background queues
- Workers handle chunking, embedding generation, and vector storage asynchronously
- This decouples user requests from heavy compute tasks
- Improves system reliability, fault tolerance, and throughput under load
This design ensures the system remains stable and responsive even with high concurrent document uploads.
🌐 Industry Insight
While working on this project, I gained deeper appreciation for the scale at which real-world AI systems operate. During my research, I learned that platforms like OpenAI rely on thousands of Kubernetes nodes (reportedly ~7,500+) to handle massive traffic, parallel workloads, and large-scale model inference.
This insight reinforced the importance of:
- Distributed systems
- Asynchronous processing
- Queue-based architectures
- Horizontal scaling with container orchestration
Designing Ragify with background workers and async queues was a step toward understanding how production-grade AI systems are built to operate reliably at scale.
🔮 Future Scope
- Build a user-friendly web UI for document upload, indexing status, and query interaction
- Add progress tracking and retry mechanisms for failed indexing jobs
- Support additional document formats beyond PDFs
- Implement multi-tenant isolation and usage limits for large-scale deployments
🚀 Impact & Learnings
Building Ragify provided hands-on experience with:
- Retrieval-Augmented Generation (RAG) architectures
- Chunking strategies and embedding pipelines
- Vector databases and semantic search
- Context injection techniques for improving LLM reliability
Ragify demonstrates how combining retrieval with generation leads to more trustworthy, production-ready AI systems.