

The Thundering Herd Problem
A business Nightmare. A massive number of concurrent requests overwhelm a server all at once.
What is the Thundering Herd Problem?
What does the term "Thundering Herd" mean? This term came from an analogy where all the animals run in one direction to achieve a goal, which leads to a bottleneck and congestion. In distributed systems, this translates to a scenario where a massive number of concurrent requests overwhelm a server or service all at once. In other words, too many cooks spoil the broth.
Let's understand this with an example.
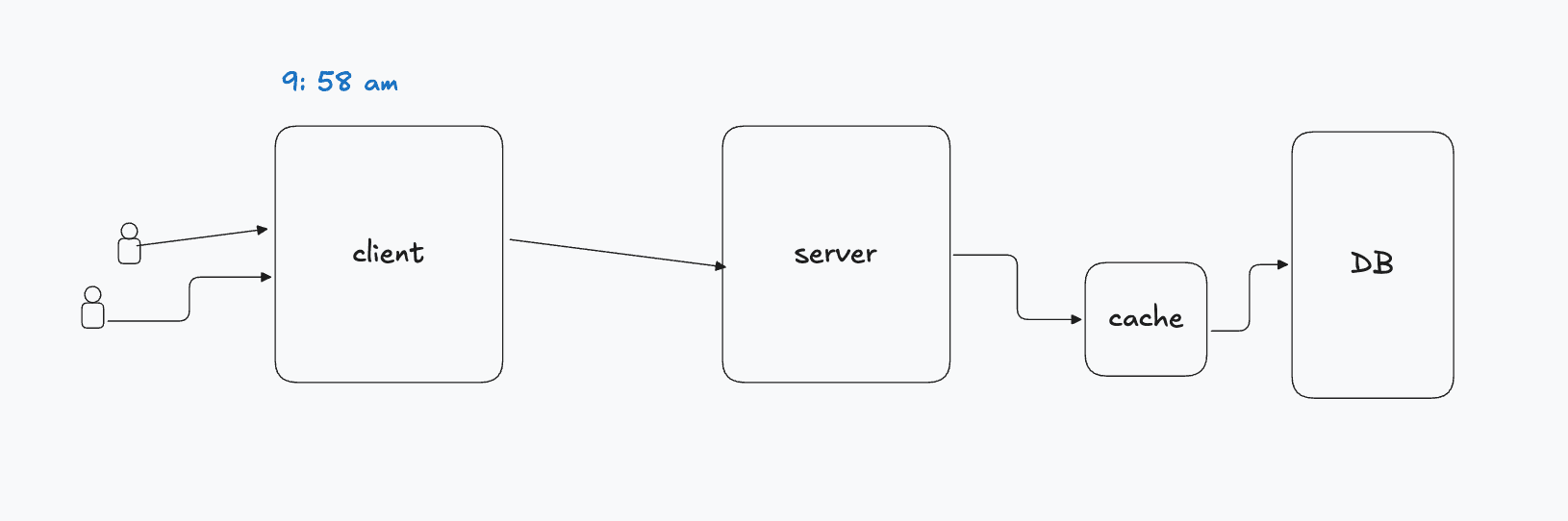
There is a big supermarket where 1000 people come for shopping. In this supermarket, there is an entry pass (think of it as an authentication token or a cache entry) which is given to customers and it has a TTL (Time To Live) of 30 days. Without this entry pass, customers are not allowed to enter the supermarket due to store policy.
On weekdays, the footfall is around 500 to 600 people, this is your baseline traffic or steady-state load. But on weekends, all 1000 people visit the mall, this represents your peak traffic or traffic spike.
Now here's where it gets interesting.
Today is a weekend and it's the end of the month, the TTL of the entry pass, which was set to 30 days at the time of creation, is about to expire. Since all passes were issued at the same time, they all share the same expiry timestamp, this is the root cause of the problem. A perfect storm is brewing.
The supermarket opens at 10:00am. At 9:50am, the entry pass scanner machine your API gateway or load balancer) is activated. On the right-hand side, there is an office (your backend service or auth server) which issues new entry passes to customers.
At 9:55am, everything is normal, the system metrics look healthy, the office manager is enjoying his tea, calm before the storm. At 9:59am, all the entry passes simultaneously expire — a classic cache invalidation event.
10:00am — chaos.
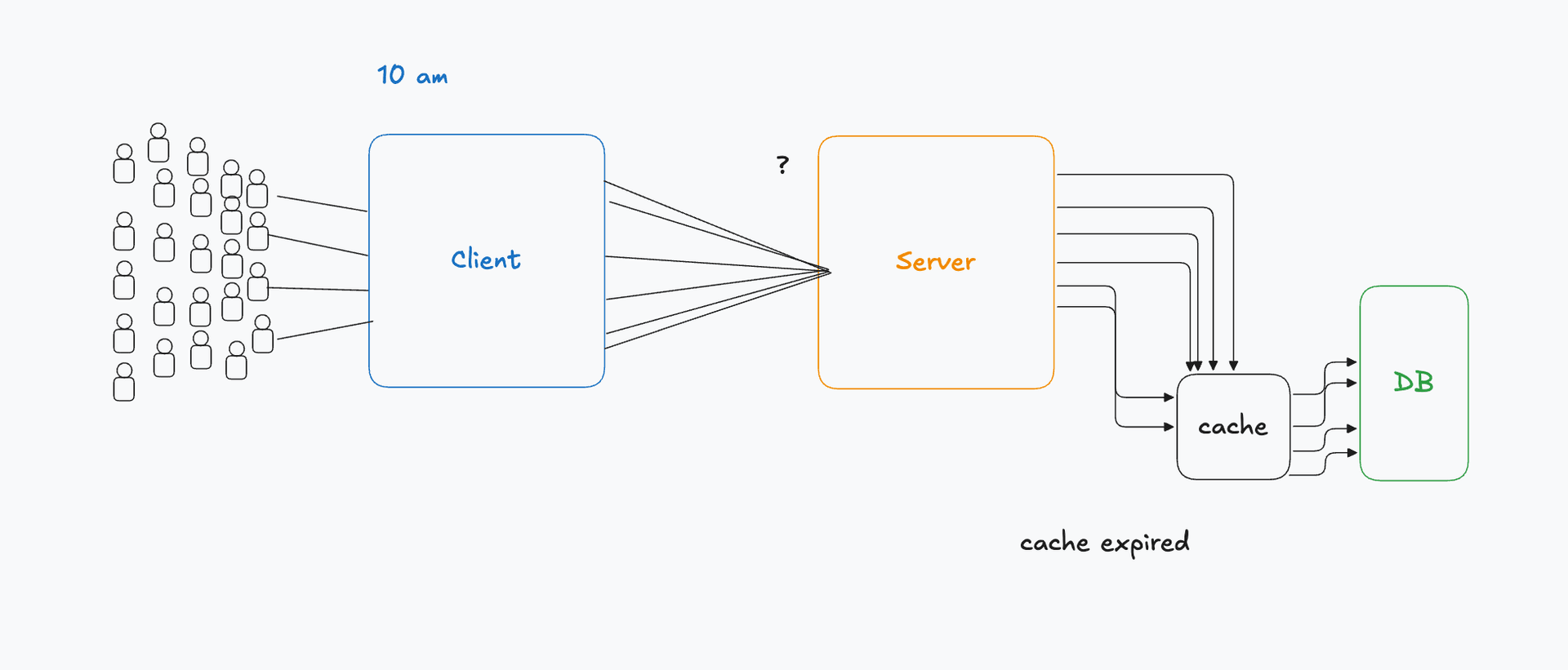
The scanner machine starts throwing errors (HTTP 401 Unauthorized or cache miss responses) for every customer. All the customers immediately rush to the office because there is a big trillion-day discount, the floodgates have opened. This is the thundering herd in action, 1000 simultaneous requests (concurrent connections) hammering a single downstream service.
The office manager looks at the rush, drops his mug of tea, and tells his 8 team members (worker threads / processes) to buckle up, "we have a traffic spike incoming!". The team hits the ground running, working at maximum throughput to regenerate entry passes (tokens) as quickly as possible. Meanwhile, the manager connects with the scheduler (auto-scaler / orchestrator like Kubernetes) to provision more resources and scale horizontally.
However, they were fighting a losing battle. The sudden surge causes resource exhaustion — CPU, memory, and connection pools are maxed out. The response times spike, SLAs are breached, and eventually the system hits a cascading failure. Some potential buyers, frustrated by the wait, leave and go home, this is your customer churn due to poor availability. There was a downtime and the team learned the hard way that failing to prepare is preparing to fail.
The lesson?
This is the Thundering Herd Problem in action. When a large number of cached entries or tokens expire simultaneously, all clients rush to the server at once, causing a massive read stampede that can trigger a system outage.
Where Does It Commonly Occur?
The Thundering Herd problem can surface at multiple layers of a system the database layer, cache layer, load balancer layer, and the server layer itself.
Database Layer The supermarket example above is a classic illustration of a database layer issue, where simultaneous cache misses cause all requests to fall through and hit the database directly, overwhelming it beyond its connection pool limit.
Load Balancer Layer The load balancer layer is another failure point. Here's how it plays out: When HTTP requests start failing, the retry mechanism kicks in automatically. If there are 1000 users online and all their requests begin to fail simultaneously, each client retries causing the request count to spike exponentially. What started as 1000 requests can quickly balloon to 3000–5000 due to retry amplification, as we discussed earlier.
A real-world example of this is Atlassian. Their load balancer failed because it was unable to handle an unexpected surge in traffic. Although AWS ELB (Elastic Load Balancer) is designed to scale, scaling is not instantaneous, and that brief window of delay was enough to cause a widespread outage.
One effective mitigation strategy for this is pre-warming. If a major feature launch, a marketing campaign, or a scheduled event is expected to significantly increase traffic, engineering teams proactively warm up their load balancer and server infrastructure ahead of time, so that auto-scaling has already kicked in before the traffic arrives, rather than scrambling to catch up after the fact.
Why Thundering Herd is dangerous in distributed systems
In distributed systems there are multiple resources connected to each other. So imagine a herd came and if there is one cpu (server) one machine then the damage is limited but if 5 machines are connected together and traffic is evenly distributed across machines then all machines (pod if using k8) react simultaneously.
Amplification Effect
- 1000 clients request same api
- cache expires
- 5 pods receive traffic evenly
each pod gets 200 requests now if each pod hits db coz cache is empty: 200 * 5 = 1000 DB hits instantly.
if you scale to 20 pods? 200 * 20 = 4000 DB hits
scaling increases amplification.
Retries Multiply the Damage Modern systems retry automatically:
- HTTP client retries
- DB driver retries
- Load balancer retries
one failed request may become 3-5 requests.
Now 1000 requests becomes 5000 which is very dangerous
Difference between normal spike vs thundering herd When there is a normal spike it is gradually increases (there is a j curve) but in thundering herd this spike is exponential (peek).
When there is normal spike if HPA is enabled in k8s then it gracefully increases the number of pods and handles the load.
In thundering herd it overwhelms the server and crashes.
Impact
CPU Exhaustion — All processes and threads wake up simultaneously, causing a massive CPU spike that further amplifies the cascading failure across the system.
Data Loss — If the database crashes without a recent backup, it can result in permanent data loss and prolonged downtime — the worst possible outcome for any production system.
Increased Latency — Even if the system manages to survive the surge, response times degrade significantly, directly impacting user experience and potentially breaching SLA (Service Level Agreement) commitments.
Techniques to Prevent the Thundering Herd Problem
-
Request Coalescing Popularised by Facebook, request coalescing is a technique where multiple identical requests arriving at the server are grouped into a single upstream request. Instead of forwarding all 1000 requests to the backend, only one request is sent while the rest wait in a queue. Once the response is received, it is fanned out and shared with all waiting clients, significantly reducing the load on downstream services.
-
Mutex (Distributed Lock) A mutex ensures that only one thread or process can access a critical section at a time. Note that this lock is assigned to a thread, not to an HTTP request directly. When the first request arrives and the cache is empty, it acquires a temporary lock and proceeds to fetch data from the database. All subsequent threads recognise the lock and wait rather than hammering the database simultaneously. Once the data is fetched and the lock is released, the waiting threads are served.
-
Cache Locking (Cache Stampede Prevention) Cache locking is closely related to the mutex concept but applied specifically at the cache layer. When a cache entry expires, instead of allowing all requests to simultaneously bypass the cache and hit the database, only one request is granted a lock to fetch fresh data from the database. All other requests wait in the queue. Once the cache is rebuilt, the lock is released and all queued requests are served directly from the cache preventing a cache stampede.
-
Staggered Expiry (TTL Jitter) Also known as Jitter Delay, this technique assigns slightly randomised expiration times to cache entries rather than setting a uniform TTL across all of them. Instead of every cache entry expiring at the exact same timestamp, they expire gradually across a time window, spreading the database load evenly and eliminating the thundering herd at its root cause. For example, instead of all entries expiring at exactly T + 30 days, each entry is assigned a TTL of 30 days ± random(0, 5 minutes).
-
Exponential Backoff When a client fails to connect to a backend service or database, naive retry logic will immediately resend the request, which often makes the situation significantly worse. Exponential backoff introduces progressively increasing wait times between each retry attempt: 1s → 2s → 4s → 8s → 16s ... This gives the system breathing room to recover rather than being buried under a relentless wave of retries. Most production systems also pair this with a maximum retry limit and jitter on the backoff intervals to avoid multiple clients retrying in perfect synchrony, which would itself create a mini thundering herd.
-
Rate Limiting restricts the number of requests a client or service can make within a given time window. Once the threshold is exceeded, further requests are either queued or rejected with an appropriate error response (HTTP 429 Too Many Requests). This acts as a traffic governor, ensuring no single client or event can overwhelm the system. Common rate limiting algorithms include:
Leaky Bucket — requests are processed at a constant rate, excess requests overflow Token Bucket — clients consume tokens per request; tokens replenish over time Sliding Window Counter — tracks request counts over a rolling time window for more precise control
As seen in the Stripe case study earlier, rate limiting is one of the most battle-tested, production-grade defences against the thundering herd problem.
Thanks for reading! Follow me on X at @viraj


